|
|
@@ -1,197 +0,0 @@
|
|
|
-Wukong Engine Codelab
|
|
|
-====
|
|
|
-
|
|
|
-At the end of this codelab, you will be able to write a simple full-text search website using Wukong engine.
|
|
|
-
|
|
|
-If you do not know how to code in Go yet, [here](http://tour.golang.org/#1) is a tutorial.
|
|
|
-
|
|
|
-## Engine basics
|
|
|
-
|
|
|
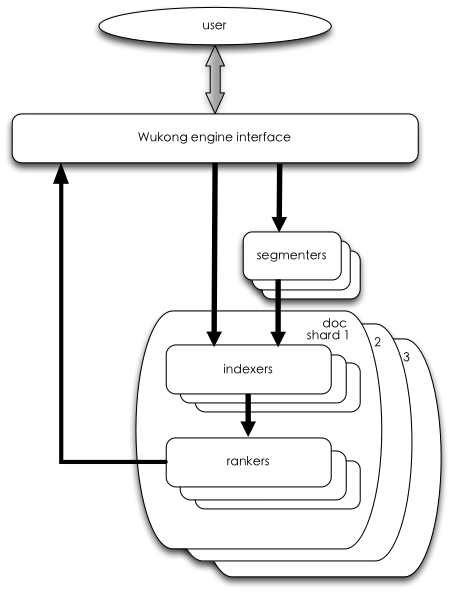
-Wukong handles user requests, segmentation, indexing and ranking in different goroutines.
|
|
|
-
|
|
|
-1. main goroutine, responsible for user interfacing
|
|
|
-2. segmenter goroutines, for tokenization and Chinese word segmentation
|
|
|
-3. indexer goroutines, for building inverted index and performing lookup
|
|
|
-4. ranker goroutines, for scoring and ranking documents
|
|
|
-
|
|
|
-
|
|
|
-
|
|
|
-**Indexing pipeline**
|
|
|
-
|
|
|
-When a document indexing request is received from the user, the main goroutine sends the doc via a channel to a segmenter goroutine, which tokenizes/segments the text and passes it to a indexer. Indexer builds search keyword index from the doc. Custom data fields for ranking are also saved in a ranker.
|
|
|
-
|
|
|
-**Search pipeline**
|
|
|
-
|
|
|
-Main goroutine receives a search request from the user, segments the query and passes it to an indexer goroutine. The indexer looks up a list of documents that satisfies the search condition. The list is then passed to a ranker to be scored, filtered and ranked. Finally the ranked docs are passed to the main goroutine through callback channel and returned to the user.
|
|
|
-
|
|
|
-In order to improve concurrency at search time, documents are sharded based on content and docids (number of shards can be specified by the user) -- indexing and search requests are sent to all shards in parallel, and ranked docs are merged in the main goroutine before returning to the user.
|
|
|
-
|
|
|
-Above gives you the basic idea on how Wukong works. A search system often consists of four parts, **document crawling**, **indexing**, **search** and **rendering**. I will explain them in following sections.
|
|
|
-
|
|
|
-## Doc crawling
|
|
|
-
|
|
|
-The docs to be crawled are [Weibo](http://en.wikipedia.org/wiki/Sina_Weibo) posts. Doc crawling itself deserves a full article, but fortunately for Weibo crawling, there's an easy-to-use [Weibo API](http://github.com/huichen/gobo) written in Go which allows fetching data with high concurrency.
|
|
|
-
|
|
|
-I've downloaded about one hundred thousand weibo posts and stored them in testdata/weibo_data.txt, so you do not need to do it yourself. One line of the file has following format:
|
|
|
-
|
|
|
- <Weibo id>||||<timestamp>||||<User id>||||<user name>||||<share counts>||||<comment counts>||||<fav counts>||||<thumbnail URL>||||<large image URL>||||<body>
|
|
|
-
|
|
|
-Weibos are saved in this struct (only stored fields used by the codelab)
|
|
|
-
|
|
|
-```go
|
|
|
-type Weibo struct {
|
|
|
- Id uint64
|
|
|
- Timestamp uint64
|
|
|
- UserName string
|
|
|
- RepostsCount uint64
|
|
|
- Text string
|
|
|
-}
|
|
|
-```
|
|
|
-
|
|
|
-If you are interested in how Weibo crawling works, here's the script [testdata/crawl_weibo_data.go](/testdata/crawl_weibo_data.go).
|
|
|
-
|
|
|
-## Indexing
|
|
|
-
|
|
|
-To use Wukong engine you need to import two packages
|
|
|
-
|
|
|
-```go
|
|
|
-import (
|
|
|
- "github.com/huichen/wukong/engine"
|
|
|
- "github.com/huichen/wukong/types"
|
|
|
-)
|
|
|
-```
|
|
|
-The first one implements the engine, and the second package defines common structs. The engine has to be initialized before use, for example,
|
|
|
-
|
|
|
-```go
|
|
|
-var search engine.Engine
|
|
|
-searcher.Init(types.EngineInitOptions{
|
|
|
- SegmenterDictionaries: "../../data/dictionary.txt",
|
|
|
- StopTokenFile: "../../data/stop_tokens.txt",
|
|
|
- IndexerInitOptions: &types.IndexerInitOptions {
|
|
|
- IndexType: types.LocationsIndex,
|
|
|
- },
|
|
|
-})
|
|
|
-```
|
|
|
-
|
|
|
-[Types.EngineInitOptions](/types/engine_init_options.go) defines options in engine initialization, such as where to load dictionary files for segmentation, stopwords, type of inverted index table, BM25 parameters, default search options, pagination options, etc.
|
|
|
-
|
|
|
-You must choose IndexerInitOptions.IndexType carefully. There are three types of index table:
|
|
|
-
|
|
|
-1. DocIdsIndex, provides the most basic index where only docids are stored.
|
|
|
-2. FrequenciesIndex, in addition to DocIdsIndex, frequencies of tokens are stored so we can compute BM25 relevance.
|
|
|
-3. LocationsIndex, which also stores each token's locations in a document, in order to compute token proximity.
|
|
|
-
|
|
|
-From top to bottom, with more computing power, it also consumes more memory, especially for LocationsIndex when documents are long. Please choose according to your need.
|
|
|
-
|
|
|
-Now you can add documents to the index, like following,
|
|
|
-
|
|
|
-```go
|
|
|
-searcher.IndexDocument(docId, types.DocumentIndexData{
|
|
|
- Content: weibo.Text, // Weibo struct is defined above. Content must be in UTF-8.
|
|
|
- Fields: WeiboScoringFields {
|
|
|
- Timestamp: weibo.Timestamp,
|
|
|
- RepostsCount: weibo.RepostsCount,
|
|
|
- },
|
|
|
-})
|
|
|
-```
|
|
|
-
|
|
|
-DocId must be unique for each doc. Wukong engine allows you to add three types of index data:
|
|
|
-
|
|
|
-1. Content of the document (Content field), which will be tokenized and added to the index.
|
|
|
-2. You can also add tokens (Tokens field) directly when the Content is empty. This allows you to bypass the built-in tokenzier and use any tokenization scheme you want.
|
|
|
-3. Document labels (Labels field), such as Weibo author, category, etc. Labels can be phrases that don't appear in the content.
|
|
|
-4. Custom scoring fields (Fields), which allows you to add any type of data for ranking purpose. 'Search' section below will talk more on this.
|
|
|
-
|
|
|
-Note that **tokens** and **labels** make up search **keywords**. Please remember the difference of the three concepts since documentation and code will mention them many times. For example, say a document has "bicycle" as a token and a "fitness" label, but "fitness" doesn't appear in content, when the query "bicycle" token + "fitness" label combination is searched, the article will be looked up. The purpose of having document labels is to quickly reduce number of documents using non-literal scopes.
|
|
|
-
|
|
|
-The Engine adds indices asynchronously, so when IndexDocument returns the doc may not yet be actually indexed. If you need to wait before further operation, call following function
|
|
|
-
|
|
|
-```go
|
|
|
-searcher.FlushIndex()
|
|
|
-```
|
|
|
-
|
|
|
-## Search
|
|
|
-
|
|
|
-Search is done in two steps. The first step is to look up documents in inverted index table which contains the keywords. This part has been explained in details before. The second step is to score and to rank the indexed documents.
|
|
|
-
|
|
|
-Wukong engine allows you to use any scoring criteria you want in ranking. Taking the Weibo search as an example, we define scoring rules as follow,
|
|
|
-
|
|
|
-1. first sort by token proximity, for example for search query "bicycle sports", the phrase will be cut into two tokens, "bicycle" and "sports". A document with the two tokens next to each other in the same order will appear above other docs.
|
|
|
-2. then rank roughly by Weibo's creation timestamp (3 days per batch).
|
|
|
-3. finally sort by Weibo's BM25 * (1 + <shard count> / 10000)
|
|
|
-
|
|
|
-To use such rule, we need to store scoring fields in the ranker. Following structure is defined
|
|
|
-```go
|
|
|
-type WeiboScoringFields struct {
|
|
|
- Timestamp uint64
|
|
|
- RepostsCount uint64
|
|
|
-}
|
|
|
-```
|
|
|
-You may have noticed, this is exactly the same type passed to the indexer when calling IndexDocument function (in fact, the function argument has the type of interface{}, so you can pass in anything you want).
|
|
|
-
|
|
|
-Now define the scoring criteria,
|
|
|
-```go
|
|
|
-type WeiboScoringCriteria struct {
|
|
|
-}
|
|
|
-
|
|
|
-func (criteria WeiboScoringCriteria) Score (
|
|
|
- doc types.IndexedDocument, fields interface {}) []float32 {
|
|
|
- if reflect.TypeOf(fields)! = reflect.TypeOf(WeiboScoringFields{}) {
|
|
|
- return []float32{}
|
|
|
- }
|
|
|
- wsf: = fields.(WeiboScoringFields)
|
|
|
- output: = make([]float32, 3)
|
|
|
- if doc.TokenProximity > MaxTokenProximity { // step 1
|
|
|
- output[0] = 1.0 / float32(doc.TokenProximity)
|
|
|
- } else {
|
|
|
- output[0] = 1.0
|
|
|
- }
|
|
|
- output[1] = float32(wsf.Timestamp / (SecondsInADay * 3)) // step 2
|
|
|
- output[2] = float32(doc.BM25 * (1 + float32(wsf.RepostsCount) / 10000)) // step 3
|
|
|
- return output
|
|
|
-}
|
|
|
-```
|
|
|
-WeiboScoringCriteria inherits types.ScoringCriteria interface and implements the Score function. This function takes two arguments:
|
|
|
-
|
|
|
-1. A types.IndexedDocument slice with information about indexed docs, such as token frequencies, token locations, BM25 score, token proximity score, etc.
|
|
|
-2. The second argument has the type of interface{}. You can think it as the void pointer in C language, which allows it to point to any data type. In our example, the data is a WeiboScoringFields struct, whose type was checked in the Score function using reflection mechanism.
|
|
|
-
|
|
|
-With custom scoring criteria, search is made easy and customizable. Code example for searching,
|
|
|
-
|
|
|
-```go
|
|
|
-response: = searcher.Search(types.SearchRequest {
|
|
|
- Text: "cycling sports",
|
|
|
- RankOptions: &types.RankOptions{
|
|
|
- ScoringCriteria: & WeiboScoringCriteria{},
|
|
|
- OutputOffset: 0,
|
|
|
- MaxOutputs: 100,
|
|
|
- },
|
|
|
-})
|
|
|
-```
|
|
|
-
|
|
|
-Text is the search phrase (must be in UTF-8). As the same as in indexing, Wukong engine allows you to bypass the built-in segmenter and to enter tokens and labels directly. See types.SearchRequest struct in the code. RankOptions defines options used in scoring and ranking. WeiboScoringCriteria is our scoring criteria defined above. OutputOffset and MaxOutputs parameters are set to control output pagination. Search results are returned in a types.SearchResponse struct that contains query's segmented tokens and their locations in each doc, which can be used to generate search snippets.
|
|
|
-
|
|
|
-## Rendering
|
|
|
-
|
|
|
-The final step to complete the search is rendering the ranked docs in front of the user. The usual practice is to make a backend service with the search engine, and then let the frontend calls the BE through JSON. Since it's not directly related to Wukong, I'm skipping the details here.
|
|
|
-
|
|
|
-## Summary
|
|
|
-
|
|
|
-Now you should have all the knowledge to finish the example, and I strongly encourage to do so by yourself. However if you don't have patience, here's the completed code [examples/codelab/search_server.go](/examples/codelab/search_server.go), which has less than 200 lines. Running it is simple. Just enter examples/codelab directory and type
|
|
|
-
|
|
|
- go run search_server.go
|
|
|
-
|
|
|
-Wait for a couple seconds until indexing is done and then open [http://localhost:8080](http://localhost:8080) in your browser. The page implements a simplified version of following site
|
|
|
-
|
|
|
-http://soooweibo.com
|
|
|
-
|
|
|
-If you want to learn more about Wukong engine, I suggest you read the code directly,
|
|
|
-
|
|
|
- /core core components, including the indexer and ranker
|
|
|
- /data tokenization dictionary and stopword file
|
|
|
- /docs documentation
|
|
|
- /engine engine, implementation of main/segmenter/indexer/ranker goroutines
|
|
|
- /examples examples and benchmark code
|
|
|
- /testdata test data
|
|
|
- /types common structs
|
|
|
- /utils common functions
|

{kind=link}